Benchmark 🧪
What is it?
Simply put: benchmarking here means putting LLMs through real assessments, using precise questions and expecting clear, targeted answers. For developers, think of it as an end-to-end test without any mocks, just actual calls to the LLM provider. We run the same method with different inputs to verify that the outputs consistently meet expectations.
Importantly, the benchmark doesn’t check every word of the response. Instead, it validates the overall result. For example, if we ask for a score for the beauty of a T-Shirt and respond with 81, we check that the score falls within 70-90, not that the score is exactly 81.
Why Benchmark LLM Features?
Treating benchmarks like end-to-end tests ensures everything works as expected, even as you tweak prompts, models updates, adjust temperature, or refactor workflows. This way, you can confidently make changes without losing sight of the final goal.
Smart Recommendation
When you use a module without specifying a model or provider, ActiveGenie automatically selects the best performer based on the latest benchmarks. The selection process considers three key factors:
- Precision: How accurate the model is on average.
- Variance: How much the model's results fluctuate (lower is better for stability).
- Cost: How much you pay per request (lower is better, especially for frequent use).
To balance these, we calculate a recommendation score for each model using the formula:
Recommendation Score = (Avg Precision / 100) - (Normalized Variance + Normalized Cost × 0.5)
Where:
- Normalized Variance = (Max Precision - Min Precision) / 100
- Normalized Cost = Cost / Max Cost
The model with the highest recommendation score is chosen for each module. The table below shows the overall best performers.
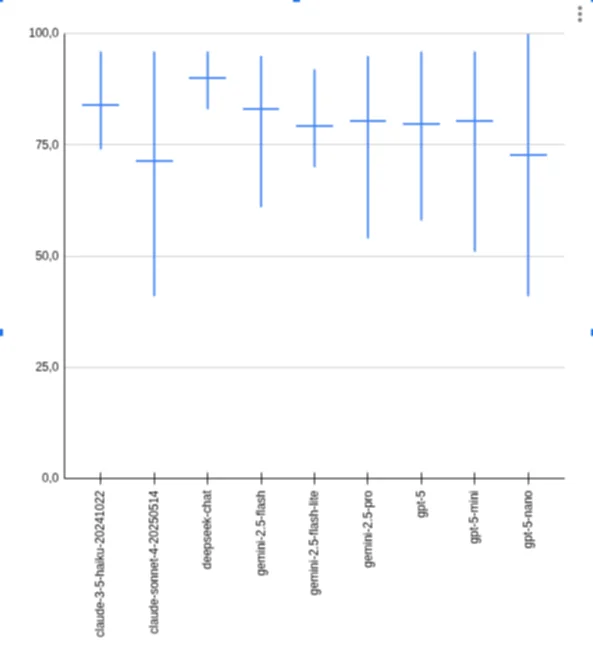
| Model | MIN Precision | MAX Precision | Avg Precision | Cost per run ($) | Recommendation Score |
|---|---|---|---|---|---|
| deepseek-chat | 83.0 | 96.0 | 90.0 | 0.7 | 0.7 |
| gemini-2.5-flash-lite | 70.0 | 92.0 | 79.2 | 0.3 | 0.6 |
| claude-3-5-haiku-20241022 | 74.0 | 96.0 | 84.0 | 3.5 | 0.4 |
| gemini-2.5-flash | 61.0 | 95.0 | 83.1 | 2.8 | 0.3 |
| gpt-5-mini | 51.0 | 96.0 | 80.4 | 1.8 | 0.2 |
| gpt-5 | 58.0 | 96.0 | 79.7 | 4.2 | 0.1 |
| gpt-5-nano | 41.0 | 100.0 | 72.8 | 0.6 | 0.1 |
| gemini-2.5-pro | 54.0 | 95.0 | 80.3 | 6.3 | -0.1 |
| claude-sonnet-4-20250514 | 41.0 | 96.0 | 71.3 | 4.1 | -0.1 |
Module by module benchmark
Extractor Module Benchmark Results
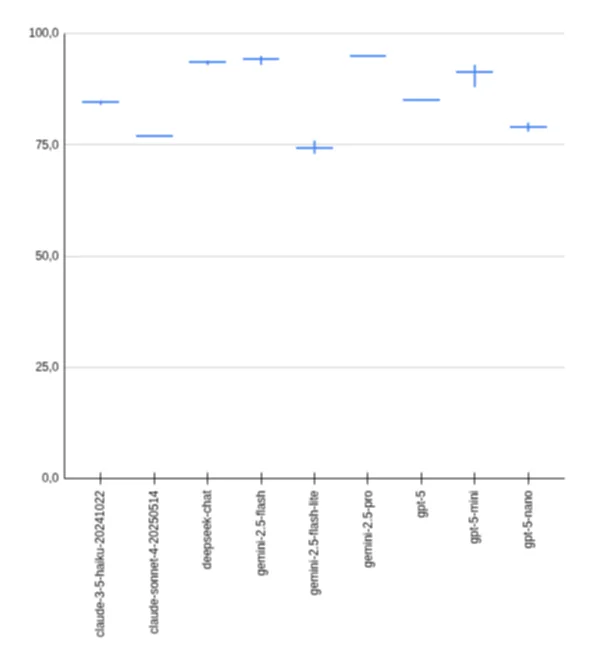
Smart recommendation:
- deepseek-chat
- gemini-2.5-flash
- gpt-5-mini
| # | Provider | Model | Tests | Precision | Duration (s) | Requests | Tokens | Avg. Duration (s) | cost |
|---|---|---|---|---|---|---|---|---|---|
| 17003761591 | anthropic | claude-3-5-haiku-20241022 | 101/18 (120) | 84 | 518.6 | 155 | 203751 | 4.30 | 0.8 |
| 17008403285 | anthropic | claude-3-5-haiku-20241022 | 103/16 (120) | 85 | 520.4 | 156 | 204635 | 4.34 | 0.81854 |
| 17008682819 | anthropic | claude-3-5-haiku-20241022 | 102/17 (120) | 85 | 515.8 | 155 | 203790 | 4.32 | 0.81516 |
| 17009564599 | anthropic | claude-sonnet-4-20250514 | 93/8 (120) | 77 | 624.7 | 138 | 178859 | 5.21 | 2.682885 |
| 17003761591 | deepseek | deepseek-chat | 113/7 (120) | 94 | 1402.4 | 162 | 145352 | 13.49 | 0.1598872 |
| 17008403285 | deepseek | deepseek-chat | 113/7 (120) | 94 | 1484.0 | 163 | 145826 | 12.37 | 0.1604086 |
| 17008682819 | deepseek | deepseek-chat | 112/8 (120) | 93 | 1619.3 | 164 | 146326 | 11.69 | 0.1609586 |
| 17003761591 | gemini-2.5-flash | 112/8 (120) | 93 | 406.7 | 164 | 212730 | 3.53 | 0.531825 | |
| 17008403285 | gemini-2.5-flash | 114/6 (120) | 95 | 147.1 | 166 | 212434 | 3.50 | 0.531085 | |
| 17008682819 | gemini-2.5-flash | 114/6 (120) | 95 | 419.8 | 166 | 215803 | 3.39 | 0.5 | |
| 17003761591 | gemini-2.5-flash-lite | 88/19 (120) | 73 | 174.9 | 148 | 153896 | 1.40 | 0.0615584 | |
| 17008403285 | gemini-2.5-flash-lite | 92/18 (120) | 76 | 423.7 | 151 | 155202 | 1.46 | 0.0620808 | |
| 17008682819 | gemini-2.5-flash-lite | 89/19 (120) | 74 | 168.5 | 147 | 153459 | 1.23 | 0.0613836 | |
| 17009564599 | gemini-2.5-pro | 115/5 (120) | 95 | 1769.8 | 163 | 261064 | 14.75 | 3.9 | |
| 17003761591 | openai | gpt-5-nano | 94/26 (120) | 78 | 925.3 | 145 | 250510 | 7.59 | 0.100204 |
| 17008403285 | openai | gpt-5-nano | 95/25 (120) | 79 | 1419.4 | 150 | 257781 | 7.90 | 0.1031124 |
| 17008682819 | openai | gpt-5-nano | 96/24 (120) | 80 | 947.4 | 150 | 257617 | 7.71 | 0.1030468 |
| 17003761591 | openai | gpt-5-mini | 112/8 (120) | 93 | 1331.0 | 153 | 184194 | 12.97 | 0.368388 |
| 17008403285 | openai | gpt-5-mini | 106/14 (120) | 88 | 910.2 | 155 | 185264 | 11.09 | 0.370528 |
| 17008682819 | openai | gpt-5-mini | 112/8 (120) | 93 | 1556.4 | 157 | 191658 | 11.83 | 0.383316 |
| 17009564599 | openai | gpt-5 | 102/18 (120) | 85 | 2004.4 | 163 | 247734 | 16.70 | 2.47734 |
Comparator Module Benchmark Results
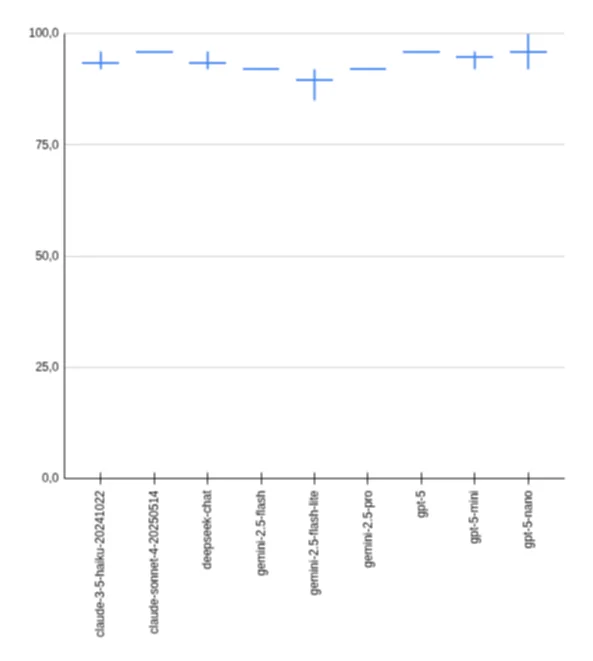
Smart recommendation:
- claude-sonnet-4-20250514
- deepseek-chat
- gpt-5
Summary Table:
| Run | Provider | Model | Tests | Precision | Duration (s) | Requests | Tokens | Avg. Duration (s) | Cost ($) |
|---|---|---|---|---|---|---|---|---|---|
| 17003761591 | anthropic | claude-3-5-haiku-20241022 | 27/1 (28) | 96 | 206.8 | 28 | 41331 | 7.35 | 0.165324 |
| 17008403285 | anthropic | claude-3-5-haiku-20241022 | 26/2 (28) | 92 | 203.7 | 28 | 41198 | 7.28 | 0.164792 |
| 17008682819 | anthropic | claude-3-5-haiku-20241022 | 26/2 (28) | 92 | 205.8 | 28 | 41295 | 7.39 | 0.2 |
| 17009564599 | anthropic | claude-sonnet-4-20250514 | 27/1 (28) | 96 | 458.0 | 28 | 48338 | 16.36 | 0.72507 |
| 17003761591 | deepseek | deepseek-chat | 27/1 (28) | 96 | 486.1 | 28 | 30420 | 21.34 | 0.0 |
| 17008403285 | deepseek | deepseek-chat | 26/2 (28) | 92 | 522.9 | 28 | 30352 | 18.68 | 0.0333872 |
| 17008682819 | deepseek | deepseek-chat | 26/2 (28) | 92 | 597.5 | 28 | 30275 | 17.36 | 0.0333025 |
| 17003761591 | gemini-2.5-flash | 26/2 (28) | 92 | 249.7 | 28 | 71938 | 9.41 | 0.179845 | |
| 17008403285 | gemini-2.5-flash | 26/2 (28) | 92 | 77.8 | 28 | 72537 | 9.37 | 0.1813425 | |
| 17008682819 | gemini-2.5-flash | 26/2 (28) | 92 | 262.4 | 28 | 73913 | 8.92 | 0.1847825 | |
| 17003761591 | gemini-2.5-flash-lite | 26/2 (28) | 92 | 178.1 | 28 | 35817 | 3.15 | 0.0143268 | |
| 17008403285 | gemini-2.5-flash-lite | 24/3 (28) | 85 | 263.6 | 28 | 35783 | 6.36 | 0.0143132 | |
| 17008682819 | gemini-2.5-flash-lite | 26/2 (28) | 92 | 88.2 | 28 | 35786 | 2.78 | 0.0 | |
| 17009564599 | gemini-2.5-pro | 26/2 (28) | 92 | 579.4 | 28 | 78885 | 20.69 | 1.183275 | |
| 17003761591 | openai | gpt-5-nano | 27/1 (28) | 96 | 530.4 | 28 | 124047 | 18.68 | 0.0496188 |
| 17008403285 | openai | gpt-5-nano | 28/0 (28) | 100 | 673.4 | 28 | 123731 | 19.00 | 0.0494924 |
| 17008682819 | openai | gpt-5-nano | 26/2 (28) | 92 | 531.9 | 28 | 124299 | 18.94 | 0.0497196 |
| 17008403285 | openai | gpt-5-mini | 27/1 (28) | 96 | 645.1 | 28 | 64983 | 23.04 | 0.1 |
| 17003761591 | openai | gpt-5-mini | 26/2 (28) | 92 | 523.1 | 28 | 63842 | 26.43 | 0.127684 |
| 17008682819 | openai | gpt-5-mini | 27/1 (28) | 96 | 740.0 | 28 | 68275 | 24.05 | 0.13655 |
| 17009564599 | openai | gpt-5 | 27/1 (28) | 96 | 1174.8 | 28 | 102010 | 41.96 | 1.0201 |
Scorer Module Benchmark Results
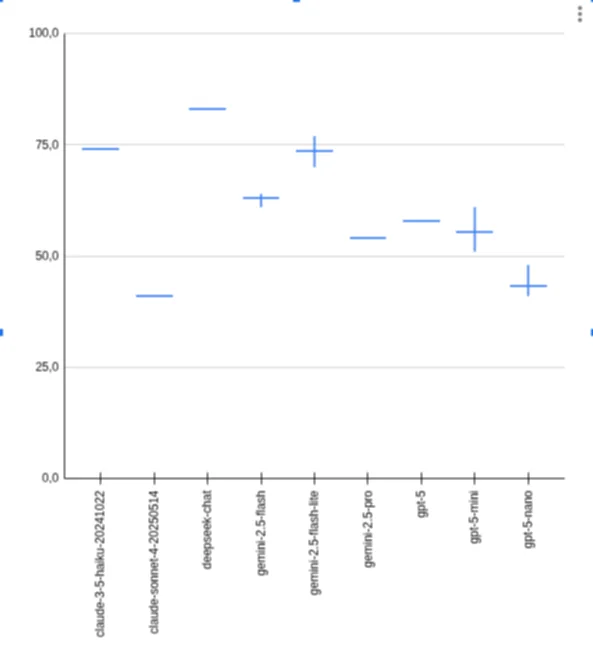
Smart recommendation:
- deepseek-chat
- claude-3-5-haiku-20241022
- gemini-2.5-flash-lite
Summary Table:
| Run | Provider | Model | Tests | Precision | Duration (s) | Requests | Tokens | Avg. Duration (s) | Cost ($) |
|---|---|---|---|---|---|---|---|---|---|
| 17003761591 | anthropic | claude-3-5-haiku-20241022 | 23/8 (31) | 74 | 282.3 | 31 | 49377 | 8.94 | 0.198 |
| 17008403285 | anthropic | claude-3-5-haiku-20241022 | 23/8 (31) | 74 | 275.6 | 31 | 49205 | 8.89 | 0.197 |
| 17008682819 | anthropic | claude-3-5-haiku-20241022 | 23/8 (31) | 74 | 277.1 | 31 | 49630 | 9.11 | 0.199 |
| 17009564599 | anthropic | claude-sonnet-4-20250514 | 13/12 (31) | 41 | 347.3 | 25 | 43490 | 11.20 | 0.652 |
| 17003761591 | deepseek | deepseek-chat | 26/5 (31) | 83 | 368.8 | 31 | 30715 | 14.11 | 0.034 |
| 17008403285 | deepseek | deepseek-chat | 26/5 (31) | 83 | 386.3 | 31 | 30711 | 12.46 | 0.034 |
| 17008682819 | deepseek | deepseek-chat | 26/5 (31) | 83 | 437.3 | 31 | 30681 | 11.90 | 0.034 |
| 17003761591 | gemini-2.5-flash | 20/11 (31) | 64 | 70.4 | 31 | 89989 | 11.19 | 0.225 | |
| 17008403285 | gemini-2.5-flash | 19/12 (31) | 61 | 322.6 | 31 | 87642 | 10.51 | 0.219 | |
| 17008682819 | gemini-2.5-flash | 20/11 (31) | 64 | 67.7 | 31 | 90343 | 10.41 | 0.226 | |
| 17003761591 | gemini-2.5-flash-lite | 22/9 (31) | 70 | 325.9 | 31 | 36490 | 2.29 | 0.015 | |
| 17008403285 | gemini-2.5-flash-lite | 23/8 (31) | 74 | 71.0 | 31 | 36940 | 2.19 | 0.015 | |
| 17008682819 | gemini-2.5-flash-lite | 24/7 (31) | 77 | 346.8 | 31 | 37843 | 2.27 | 0.015 | |
| 17009564599 | gemini-2.5-pro | 17/14 (31) | 54 | 576.4 | 31 | 81963 | 18.59 | 1.229 | |
| 17003761591 | openai | gpt-5-nano | 15/16 (31) | 48 | 303.1 | 31 | 79310 | 9.47 | 0.000 |
| 17008403285 | openai | gpt-5-nano | 13/18 (31) | 41 | 456.9 | 31 | 83972 | 10.39 | 0.034 |
| 17008682819 | openai | gpt-5-nano | 13/18 (31) | 41 | 322.0 | 31 | 82061 | 9.78 | 0.033 |
| 17003761591 | openai | gpt-5-mini | 17/14 (31) | 54 | 460.3 | 31 | 55719 | 17.01 | 0.111 |
| 17008403285 | openai | gpt-5-mini | 16/15 (31) | 51 | 293.6 | 31 | 54980 | 14.85 | 0.110 |
| 17008682819 | openai | gpt-5-mini | 19/12 (31) | 61 | 527.4 | 31 | 55412 | 14.74 | 0.111 |
| 17009564599 | openai | gpt-5 | 18/13 (31) | 58 | 677.8 | 31 | 70258 | 21.86 | 0.703 |
Lister benchmark result
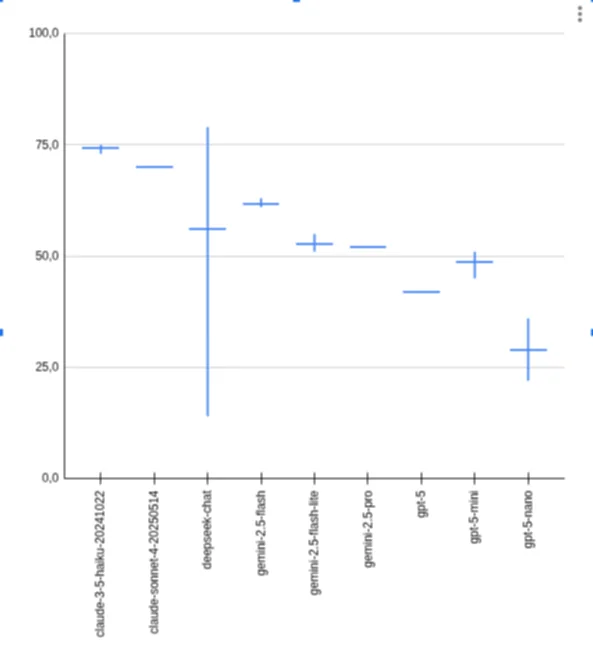
Smart recommendation:
- claude-3-5-haiku-20241022
- claude-sonnet-4-20250514
- gemini-2.5-flash
| # | Provider | Model | Tests | Precision | Duration (s) | Requests | Tokens | Avg. Duration (s) | cost |
|---|---|---|---|---|---|---|---|---|---|
| 17003761591 | anthropic | claude-3-5-haiku-20241022 | 51/17 (68) | 75 | 181.0 | 69 | 54801 | 2.70 | 0.219204 |
| 17008403285 | anthropic | claude-3-5-haiku-20241022 | 50/18 (68) | 73 | 184.3 | 69 | 54920 | 2.71 | 0.21968 |
| 17008682819 | anthropic | claude-3-5-haiku-20241022 | 51/17 (68) | 75 | 183.5 | 69 | 54800 | 2.66 | 0.2192 |
| 17009564599 | anthropic | claude-sonnet-4-20250514 | 48/20 (68) | 70 | 218.4 | 69 | 51781 | 3.21 | 0.776715 |
| 17003761591 | deepseek | deepseek-chat | 54/14 (68) | 79 | 98.8 | 69 | 27612 | 07.04 | 0.0303732 |
| 17008403285 | deepseek | deepseek-chat | 51/17 (68) | 75 | 434.1 | 69 | 27653 | 6.38 | 0.0304183 |
| 17008682819 | deepseek | deepseek-chat | 10/2 (68) | 14 | 478.8 | 12 | 4643 | 1.45 | 0.0051073 |
| 17003761591 | gemini-2.5-flash | 42/26 (68) | 61 | 280.5 | 69 | 71844 | 4.26 | 0.17961 | |
| 17008403285 | gemini-2.5-flash | 42/26 (68) | 61 | 61.9 | 69 | 73328 | 4.30 | 0.18332 | |
| 17008682819 | gemini-2.5-flash | 43/25 (68) | 63 | 292.7 | 69 | 74350 | 4.12 | 0.185875 | |
| 17003761591 | gemini-2.5-flash-lite | 36/32 (68) | 52 | 62.7 | 69 | 31319 | 1.00 | 0.0125276 | |
| 17008403285 | gemini-2.5-flash-lite | 35/33 (68) | 51 | 289.4 | 69 | 31363 | 0.92 | 0.0125452 | |
| 17008682819 | gemini-2.5-flash-lite | 38/30 (68) | 55 | 68.3 | 69 | 31176 | 0.91 | 0.0124704 | |
| 17009564599 | gemini-2.5-pro | 36/32 (68) | 52 | 930.5 | 69 | 108192 | 13.68 | 1.62288 | |
| 17003761591 | openai | gpt-5-mini | 35/33 (68) | 51 | 522.9 | 69 | 56942 | 7.59 | 0.1 |
| 17008403285 | openai | gpt-5-mini | 34/34 (68) | 50 | 352.5 | 69 | 58710 | 7.62 | 0.11742 |
| 17008682819 | openai | gpt-5-mini | 31/37 (68) | 45 | 518.3 | 69 | 58817 | 7.69 | 0.117634 |
| 17003761591 | openai | gpt-5-nano | 15/53 (68) | 22 | 340.4 | 69 | 79627 | 4.88 | 0.0 |
| 17008403285 | openai | gpt-5-nano | 20/48 (68) | 29 | 516.1 | 69 | 82001 | 05.01 | 0.0 |
| 17008682819 | openai | gpt-5-nano | 25/43 (68) | 36 | 332.1 | 69 | 83441 | 5.18 | 0.0333764 |
| 17009564599 | openai | gpt-5 | 29/39 (68) | 42 | 972.0 | 69 | 93495 | 14.29 | 0.93495 |
ranker benchmark result
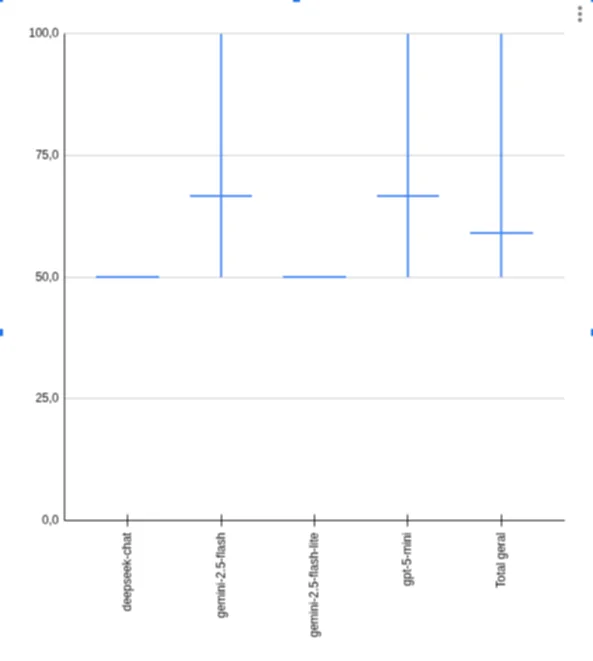
Smart recommendation:
- gemini-2.5-flash
- gpt-5-mini
| # | Provider | Model | Tests | Precision | Duration (s) | Requests | Tokens | Avg. Duration (s) | cost |
|---|---|---|---|---|---|---|---|---|---|
| 17003761591 | anthropic | claude-3-5-haiku-20241022 | 0/0 (2) | 0 | 30.3 | 24 | 34329 | 15.34 | 0.137316 |
| 17008403285 | anthropic | claude-3-5-haiku-20241022 | 0/0 (2) | 0 | 29.9 | 24 | 34438 | 14.94 | 0.137752 |
| 17008682819 | anthropic | claude-3-5-haiku-20241022 | 0/0 (2) | 0 | 30.7 | 23 | 32887 | 15.17 | 0.1 |
| 17003761591 | deepseek | deepseek-chat | 1/0 (2) | 50 | 446.6 | 205 | 289104 | 274.44 | 0.3180144 |
| 17008403285 | deepseek | deepseek-chat | 1/0 (2) | 50 | 475.8 | 201 | 279556 | 237.92 | 0.3 |
| 17008682819 | deepseek | deepseek-chat | 1/0 (2) | 50 | 548.9 | 202 | 288354 | 223.31 | 0.3171894 |
| 17003761591 | gemini-2.5-flash | 1/1 (2) | 50 | 381.6 | 138 | 599784 | 183.26 | 1.49946 | |
| 17008403285 | gemini-2.5-flash | 1/1 (2) | 50 | 160.3 | 201 | 844904 | 244.49 | 2.11226 | |
| 17008682819 | gemini-2.5-flash | 2/0 (2) | 100 | 489.0 | 166 | 688138 | 190.81 | 1.720345 | |
| 17003761591 | gemini-2.5-flash-lite | 1/1 (2) | 50 | 149.8 | 314 | 584318 | 124.40 | 0.2337272 | |
| 17008403285 | gemini-2.5-flash-lite | 0/0 (2) | 0 | 366.5 | 302 | 563459 | 74.92 | 0.2253836 | |
| 17008682819 | gemini-2.5-flash-lite | 1/1 (2) | 50 | 248.8 | 323 | 596905 | 80.15 | 0.238762 | |
| 17003761591 | openai | gpt-5-nano | 0/1 (2) | 0 | 897.6 | 269 | 1156009 | 341.14 | 0.5 |
| 17008403285 | openai | gpt-5-nano | 0/1 (2) | 0 | 1466.0 | 258 | 1112166 | 334.98 | 0.4448664 |
| 17008682819 | openai | gpt-5-nano | 0/2 (2) | 0 | 670.0 | 345 | 1569127 | 448.78 | 0.6276508 |
| 17003761591 | openai | gpt-5-mini | 1/1 (2) | 50 | 1335.2 | 389 | 1109705 | 793.78 | 2.21941 |
| 17008403285 | openai | gpt-5-mini | 1/1 (2) | 50 | 682.3 | 378 | 1083312 | 667.58 | 2.2 |
| 17008682819 | openai | gpt-5-mini | 2/0 (2) | 100 | 1587.6 | 571 | 1210776 | 732.98 | 2.421552 |
Benchmarking Stats
The latest benchmarking run involved:
- Total requests: 10,086
- Total tokens processed: 20,021,757
- Total cost: ~$45
- Estimated time (no parallelism): 14 hours 42 minutes
- Unique tests: 249 (each run up to 3 times)
- Models covered (9):
- claude-3-5-haiku-20241022
- claude-sonnet-4-20250514
- deepseek-chat
- gemini-2.5-flash
- gemini-2.5-flash-lite
- gemini-2.5-pro
- gpt-5-nano
- gpt-5-mini
- gpt-5
Running Benchmarks
To run the benchmarks yourself:
bundle exec rake active_genie:benchmarkTo benchmark a specific module:
bundle exec rake active_genie:benchmark[extractor]
bundle exec rake active_genie:benchmark[scorer]
bundle exec rake active_genie:benchmark[comparator]
bundle exec rake active_genie:benchmark[ranker]Future Improvements
- Expanded test coverage for edge cases
- Multi-language support testing